2021.6. 9
技術動向2020⑩
仮想化・クラウド時代のアーキテクチャ
「仮想化・クラウド時代のアーキテクチャ」
小川英孝 (NECソリューションイノベータ(株) プラットフォーム事業本部)
情報サービス企業がデジタルビジネスに取り組むには、どのようなスキルや技術が求められるのか。
デジタルビジネスに関わるキーワードを取り上げて、有識者に寄稿していただいた。
※「DXビジネス全体像の可視化~情報サービス産業白書2020」掲載
1 仮想化・クラウドの技術動向
A)クラウドプラットフォームサービス
クラウドはDX(Digital Transformation)推進に欠かせないICT(Information and Communication Technology)プラットフォームであり、今後も大きな成長を期待できる技術領域となっている。
クラウドコンピューティング(*1) の今後の技術動向としては、多くの企業が運用しているIaaS(Infrastructure as a Service)からインフラを意識しないマネージド型のPaaS(Platform as a Service)やSaaS(Software as a Service)にサービスモデルをシフトしていくのが妥当であり、実装モデル面はプライベートクラウドのみ/パブリッククラウドのみでなく両方のいいとこ取りのハイブリッドクラウド、さらには異なるベンダのクラウドサービスを組み合わせたマルチクラウドの時代を迎えている。
B)クラウドネイティブ技術
2018年にCNCF(Cloud Native Computing Foundation)によってクラウドネイティブの定義がなされ、コンテナ、マイクロサービス、サービスメッシュ、サーバレスコンピューティングなどの技術が特に注目されている。クラウドネイティブ技術は、パブリッククラウド、プライベートクラウド、ハイブリッドクラウドなどの近代的でダイナミックな環境において、スケーラブルなアプリケーションを構築および実行するための能力を組織にもたらす。
コンテナは、Dockerの実装に代表されるとおりIaaSとは異なる仮想化レベルを提供し、メモリフットプリントが小さく、起動も速く、簡単に構築できるなどの利点を有している。
マイクロサービスアーキテクチャは、小さな機能部品をメッセージやAPIを用いて疎結合なシステムを構成し独立性を高める技術手法となっている。
サービスメッシュは、マイクロサービスを運用する上での課題を解決するデザイン手法である。複雑なサービス関係を可視化するための仕組み、個々のサービスの運用/監視ロジックを透過的に実装する仕組みなどを有している。サービスメッシュの実装として現在最も普及しているものがIstio だ。
サーバレスコンピューティングは、サーバ管理/運用を必要としないアプリケーション実行基盤であり、それを実現するための最先端のアーキテクチャとなっている。そして、スケーラビリティの管理が不要なこと、アイドル時のコストが発生しないこと、などの特徴がある。
2 クラウド時代のアーキテクチャ
A)高可用性、スケーラブルなアーキテクチャ
スレッドモデルとC10K問題
昨今、PCやスマートフォンなど数十万ユーザにサービスを提供する時代になっており、同時接続クライアント数10,000を意識した設計/実装が不可欠となっている。これがC10K問題といわれるゆえんだ。
従来のスレッドモデルの仕組みでは、同時に10,000クライアント接続をスムーズにさばくことができる潤沢なI/Oリソースを有すシステムを構築するにはかなりのコストが必要であり、残念ながらそれに見合った高い性能を得ることも難しく、仕様に起因する根本的な課題が残る。
例えば、アプリケーションサーバの心臓部であるJavaは、仕様上、スレッド当たり1MBのスタックメモリ(Cヒープ)を割り当てるので、1,000スレッド同時にさばこうとすれば1GBのCヒープが必要であり、10,000スレッド相当なら10GBのメモリを消費する。さらにこの場合、頻繁に生ずるコンテキスト(スレッド)スイッチによって、CPUレジスタの退避・復元オーバヘッドが増大し性能劣化を引き起こす。
また、同時処理スレッド数を上げたいがゆえ、システム全体のパラメータを調整しリクエストを受けレスポンスを返すまでのI/O箇所全てでBlockingが生じないようにしたとしても、物理的なリソースには限りがあるため単位時間に処理できる上限を超えれば内部処理時間が増大していく。
結果として、スレッドモデル実装はC10K問題の解にはなり得ないことが分かる。
イベント駆動モデルとThrottling(*2)
イベント駆動モデルは、スレッドモデルに代わる実装であり、イベントループとNon-Blocking I/Oによる仕組みによってC10K問題を解決しようとするアプローチだ。
まず、イベントループはシングルスレッド構成であるため、同時接続クライアント数が10,000となった場合でも、大量のメモリリソースを消費することはなく、C10K問題の誘発もない。加えて、Non-Blocking I/Oと共にイベントループを構成することで、遅滞なく大量のリクエストを処理することができる。
さて、ここでお気付きとは思うが、C10K問題に対する解として単純にイベント駆動モデルを適用すると、例えば、フロント側から入ってくる同時リクエスト数10,000をそのままバックエンド側に渡してしまうことになるため、C10K問題をバックエンド側に丸投げしただけになりかねない。
これを解決するには、バックエンド側に渡す処理の同時最大数を絞り、バックエンドの負荷が一定以上に増大しないよう抑制する仕組みが不可欠となる。この仕組みをThrottlingと呼び、クラウド時代には欠かせない機能の一つとなっている。AWS API Gateway、OSSではHAProxy、有償版NGINX PlusなどがこのThrottling機能を有している。
非対称アーキテクチャと接続多重度アイソレーション
前述のThrottlingにも通ずるところがあるが、システムアーキテクチャを検討する場合、コンポーネントやサブシステム間の接続をM:Nとし非対称型のアーキテクチャとすることを強く推奨する。
M:N接続の非対称アーキテクチャを実現するためには、接続多重度をアイソレーションする何らかの仕組みが不可欠ではあるものの、この仕組みにより、コンポーネントやサブシステム単位での追加拡張と、異常があれば部分的に閉塞し切り離すなどの柔軟性を併せ持つことができるようになる。ここがフルスケーラブルなシステムを構成する上での一つのヒントとなる。
接続多重度をアイソレーションできるものとしては、MQ(Message Queue:図表1)やLB(Load Balancer:図表2)などが広く知られている。
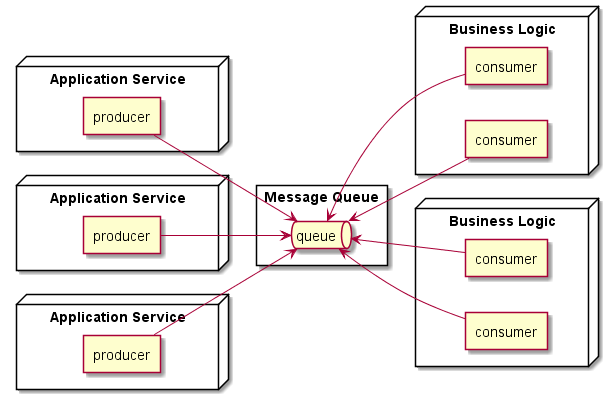
【図表1 MQを用いたM:N接続の例】
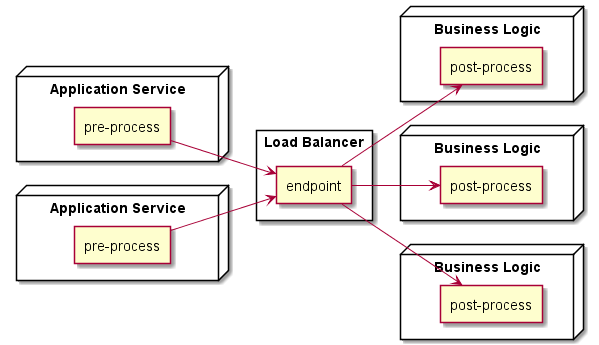
【図表2 LBを用いたM:N接続の例】
サーバレスファンクションとAPI Gateway
AWSの場合、RESTfulサービスのリファレンスアーキテクチャである、サーバレスLambdaファンクションとAPI Gatewayを組み合わせスケーラブルな構成とする実装が基本的なアプローチとなる。
API Gatewayに定義したエンドポイントにリクエストが届くと、それに紐づいたLambdaファンクションにリクエストが渡りビジネスロジックが実行される。
この構成の利点は、APIを介してI/Fと実装(ビジネスロジック)を分けることができ、さらに、画面レンダリングをモバイルアプリケーション側に寄せて開発できるため、はやりのSPA (Single Page Application)スタイルの画面デザインや、UI/UXの改善、機能強化に際し開発効率の向上を見込むことができる。
その上、API Gatewayが有すThrottlingの仕組みを用いて、Lambdaインスタンスが同時に大量に割り当てられることを防ぎ、必要以上のリソースを無駄に浪費することがないようになっている。
従来、サーバレスLambdaファンクションをVPC (Virtual Private Cloud)に配置した場合、インスタンス起動に時間がかかるという大きな弱点があったものの、2019年末Lambda周りの改善が行われ既に過去の問題となっており、今後さらなる利用が進みエンジニアの方々のサーバレス知見が蓄積されていくものと予想する。
なお、サーバレスLambdaファンクションを利用する場合はStatelessな実装とすることが常識だったが、StepFunctionsなどの新たな機能によってStatefulな実装を選択することもできるようになっている。
サーバレスコンテナとアプリケーションロードバランサ
こちらもAWSでよく用いられる、サーバレスコンテナFargateとアプリケーションロードバランサALBを組み合わせたスケーラブルな構成パターンとなる。この構成は、モノリシックな既存アプリケーションをサーバレス実装とする場合にも効果的だ。
VM(Virtual Machine)ベースのコンテナを利用する代わりに、インフラを意識する必要のないFargateを活用することで、エンジニアはビジネスロジックに集中して開発に取り組むことができ、OSセキュリティパッチ適用などホストマシンの運用管理が不要となる。
Fargateには多くのメリットがある反面、データを保持する永続化ファイルシステムをサポートしない仕様上の制約がある。例えば、稼動中に内部ファイルを更新したとしても、コンテナを停止して再起動すれば最初の状態に戻すことができる。ある意味、これはメリットであり、リードオンリーなシステムとして構成しセキュリティを高める施策に利活用した事例(*3)がある。
オートスケールによるスパイク対策
クラウドサービスを使う最大のメリットはオートスケール機能にあると言っても過言ではない。
例えば、オンプレミスやハウジングサービスの環境下で、利用者やトラフィックが増え想定以上のリクエスト負荷によって応答遅延など著しくサービスレベルが低下した場合、サーバを増強することが唯一の解となるが、購入手配には費用と手間がかかり即座に改善対処することは難しいところだ。
対して、クラウドであれば、事前にオートスケールのしきい値設定を行なっておけば、突発的なスパイクが生じて負荷が増大した場合に、自動的にインスタンスの追加起動、スケールアウトによってリクエストをさばく能力を上げることができる。逆に、負荷が下がればスケールインさせ初期構成に戻すこともできる。この時、サーバを増設する物理的なスペースを確保する必要もないため、性能面だけでなく運用コスト面でも非常に効果的だ。
B)セキュリティを担保した実装と運用保守の自動化
業界標準OpenID ConnectとIDトークン
クラウド上で何らかのサービスを始めようとした場合、認証機能の実装を避ける通ることはできないが、認証認可を含めユーザ管理を全て自システム内で行う方法と、外部のIdP (Identity Provider)を利用する方法がある。
前者は自社で認証基盤を設計構築するノウハウが必要であり多要素認証(MFA:Multi-Factor Provider)などのセキュリティ強化策が不可欠だ。実装や運用上の問題によってアカウント乗っ取りが生じた事例がある。
後者はOAuth2ベースのセキュアな認証プロトコルOpenID Connectを用いて外部IdPとID連携し、GoogleやFacebookなどのSNSアカウントを用いてユーザ管理する手法となる。この仕組みの利点は、パスワードなどの認証情報を取り扱うことなく、最小限の個人情報(アカウント名、e-mailアドレスなど)を管理するのみであり、ユーザ自身にとっても新たなアカウントを作成せずに当該サービスを利用できるメリットがある。この時、認証/認可コードをJWT (JSON Web Token)形式のIDトークンとして取り扱い、SSO (Single Sign On)認証を実現することもできる。(図表3)
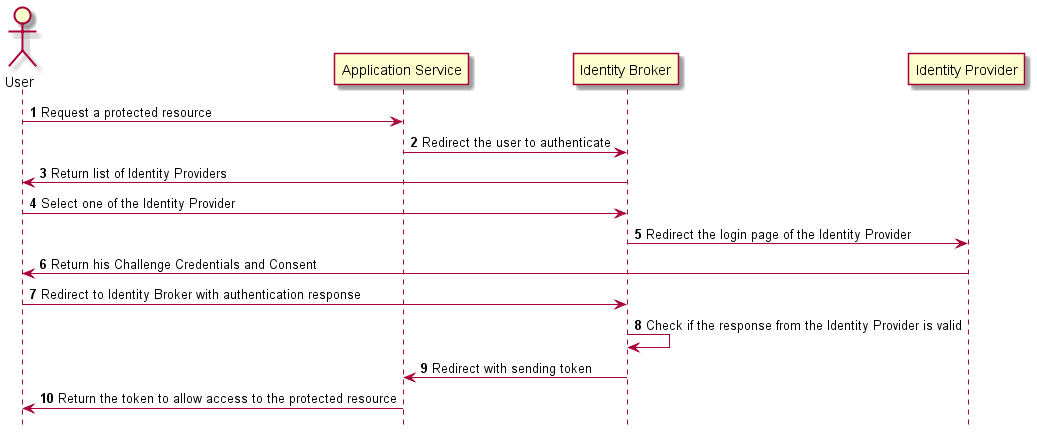
【図表3 OpenID Connect通信シーケンスの例】
外部IdPを利用するとした場合の実現方法は、いくつか選択肢がある。
a)OSSのKeycloak(*4) をIDブローカーとして構成する。(HA構成可能)
b)AWS CognitoサービスをIDブローカーとして構成する。(利用者数増による課金留意)
c)認証に特化したIDaaS (Identity as a Service)プラットフォームAuth0(*11)などをIDブローカーとして利用する。
RBAC(Role ベースアクセス制御)とマルチテナンシー
クラウド上で複数の顧客にサービスを提供する場合、組織ごとに物理的に分割してテナント管理するのが最も簡単なやり方だが、サービス開始までにリードタイムが必要であり、テナント数に比例してランニングコストが嵩むため最適なアプローチとは言えない。
サービスに柔軟性を与えて、RBAC(Role-based Access Control)を用いて組織やユーザ/グループを論理分割してマルチテナント構造とすることによって、コストを抑えつつ、顧客テナントごとに細かい権限管理が可能なサービスを提供することができる。
ユーザに対して一つ以上のロールを割り当てることができ、また、ロールそれぞれに対して一つ以上のパーミッションを割り当てることができる自由度の高いデータ構造を成し、組織やテナントを論理分割して管理できるようにすべきである。(図表4)
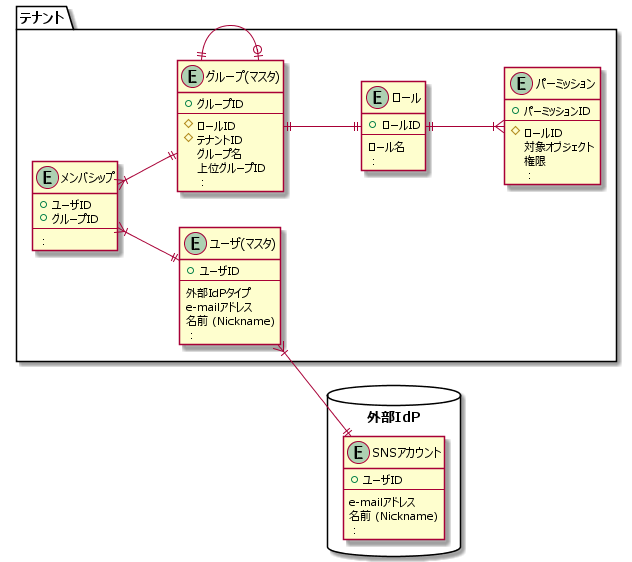
【図表4 ID連携ユーザ管理の例】
CI/CD自動化、DevOps実践
さて、サーバレスファンクションのところで述べたとおり、REST APIを介してI/Fと実装が分かれているので、CI(Continuous Integration)/CD(Continuous Delivery)パイプラインを構成してPostman/Newmanなどのテストツールを組み込むことができる。開発者による変更に対してバグがないか自動的にテストを行い、さらにビルドしたモジュールをステージング環境や本番環境に自動的にデプロイして、エンドユーザが使用できるようにする高度な自動化プロセスを実践して改善を図ることができる。
GitHubフロー、Jenkinsパイプライン、 AWS CodeBuild/CodePipeline/CodeDeploy、CircleCIなどの各種ツールを組み合わせて実現することができ、こうした自動化など改善のプロセスを進めることがDevOpsの取り組みの一つとなる。
サーバレスメトリクス収集、運用可視化
サーバレスファンクション、サーバレスコンテナなどのフルマネージドサービス利用時においても、リクエスト処理状況を可視化して自サービスが正しく動いているかを判断できるようにしておくことが重要となる。何か問題が生じた場合に備え、それをすぐに切り分け対応できるようにサービス稼働状況をモニタしておくことが不可欠だ。
AWS CloudWatch、CloudWatchLogsの他にDatadogなどを活用することで、サーバレスマネージドサービスのメトリクスを収集して監視・可視化を行うことができる。Datadogは監視・可視化に特化したマネージドクラウドサービスであり、今この分野で注目を集めているサービスプロダクトといえる。
C)クラウドネイティブアーキテクチャ5原則(参考)
・ 原則1:設計に自動化を組み込む
・ 原則2:状態をスマートに処理する
・ 原則3:マネージドサービスを選ぶ
・ 原則4:多層防御を実装する
・ 原則5:アーキテクチャを常に考える
3 クラウドネイティブ技術活用における課題
A)発展途上であること
クラウドネイティブ技術は発展途上であるがゆえ、サーバレスプラットフォームの機能追加、アップデートなど繰り返し改善が行われているところとなっている。その反面、互換性が失われたりしないか、何らかの不具合が生じた場合に要因切り分けに時間を要す可能性はないかなど、気がかりな点があるのも確かだ。
しかしながら、安定するのを待っていては後塵を拝しノウハウを蓄積することもままならない。
まずは、積極的に使って不具合報告を挙げベンダに改善を依頼していくべきだ。またコミュニティなどエンジニアの輪に参加して、回避策などをディスカッションし情報共有して解決策を探るプロアクティブな行動が必要といえる。
B)ベンダロックイン
フルマネージドなクラウドサービスを利用することでインフラを意識することなく運用負担を低減できるが、同時にベンダロックインされてしまうことは避けて通れない。
ベンダロックインによって、そのクラウドサービスで深刻な障害が生じたとしても簡単には他ベンダのサービスに移設復旧させることは困難だが、このような状況に備え、地域分散配置や高可用な構成などフルマネージドなクラウドサービスを駆使してDR(Disaster Recovery)対策まで一貫して行うことができる。
このベンダロックインをプラスと捉えるかマイナスと捉えるかは、マネージドクラウドサービスの価値を最大限に利活用できているか否かではないだろうか。まずは積極的に活用してより多くのメリットを享受できるようにしていただきたい。
(*1)The NIST Definition of Cloud Computing, SP800-145, NIST
IPA日本語訳NISTによるクラウドコンピューティングの定義(SP 800-145)
(*2)Building High-Performance Application Servers - What You Need to Know
(*3)日経クロステック:ミクシィが初のカード決済基盤に挑む、工夫凝らした新旧技術の「融合」とは
(*4)IDブローカーに関するKeycloak開発者ガイド
(*5)Auth0は2013年創業のスタートアップベンチャー、最近、国内での活用事例が増えている (2017年にNTTドコモが出資)
#アーキテクチャ#クラウド#論文
- この記事をシェアする
- この記事はいかがでしたか?