2021.4. 7
技術動向2020➂
AI
「AI」 滝 勇太 ((株)構造計画研究所 IoEビジネス推進部)
情報サービス企業がデジタルビジネスに取り組むには、どのようなスキルや技術が求められるのか。
デジタルビジネスに関わるキーワードを取り上げて、有識者に寄稿していただいた。
※「DXビジネス全体像の可視化~情報サービス産業白書2020」掲載
1 AI技術の種類
近年、AI(Artificial Intelligence)技術、特に深層学習を含む機械学習技術の発展により、分析の精度が現場水準を達成できる事例が増えてきた。また、その技術を実装したツール開発も進み、一般にも入手しやすくなったことで、様々な分野でAI活用が検討・実現されている。本稿では、AI技術の最新動向や業務活用において重要な点について言及するが、まず前提知識として機械学習技術およびその周辺技術について説明する。
「AI」という用語は非常に広い意味で用いられているが、近年のAIブームにおける代表的な技術は「機械学習」と呼ばれ、一般に「教師あり学習」、「教師なし学習」、「強化学習」の3つに分類される(図表1)。
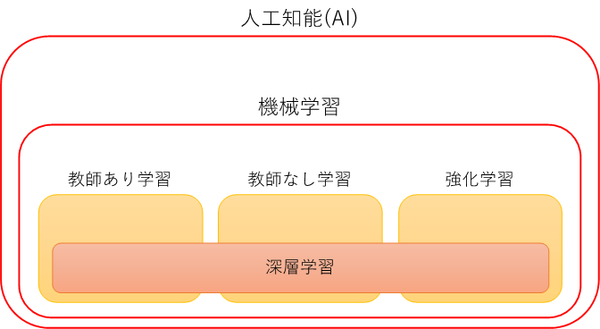
【図表1:人工知能の体系】
A)教師あり学習
入力データに対して、正解となる出力が与えられる問題設定に対して用いられる学習方法である。例えば、画像に含まれる物体の名称を判別する問題や顧客特性から商品の購買有無を予測する問題などが挙げられる。教師あり学習では、後述の教師なし学習に比べ、一般に高い精度の学習が期待できるが、その一方で、学習時に「正解データ(教師データ)」が必須であり、その教師データの作成にコストを要することがある。
B)教師なし学習
教師あり学習のように「正解」が与えられない(もしくは正解がない)データから何らかの有益な情報を抽出する学習方法である。データをいくつかのグループに分割する「クラスタリング」、前処理の一環として、データから何らかの特徴を取り出す「特徴抽出」などがこの学習方法に属する。また、仮に教師データがあっても、異常検知問題のように教師データに含まれる異常データが極端に少ないような場合には、教師なし学習を用いることがある。
C)強化学習
ある環境においてなんらかの複数の行動を実行させる。その行動の結果に対し報酬(もしくは罰則)を設定し、行動の試行錯誤の中で報酬を最大化(もしくは罰則を最小化)する一連の行動基準を学習させる方法を強化学習と呼ぶ。工場・倉庫のロボットアームのティーチングや自動運転のシミュレーション、囲碁などのゲームのAI開発が応用先として挙げられる。なお、強化学習は、「多数回の失敗(試行錯誤)」が許される課題に向いている。
D)その他のAI技術
前述の通り、近年のAI技術の代表格は機械学習であるが、以下のような技術もAIとして捉えることができる。
●エキスパートシステム
●ファジィ制御
●マルチエージェントシミュレーション
●オペレーションズ・リサーチ
●遺伝的アルゴリズム
これらの多くは第一次、第二次AIブームに開発された技術であるが、近年のIoTの発達により再注目されているものもあり、「AIによる課題解決」のための手段の候補となりうる。
2 最新技術動向
AI技術の中でも特に近年注目されているいくつかの手法および実装環境について言及する。
現在注目されているAI手法としては、以下が挙げられる。
●説明可能AI(eXplainable AI:XAI)
●敵対的生成ネットワーク(Generative Adversarial Networks:GAN)
●転移学習
●BERT(Bidirectional Encoder Represen-tations from Transformers)
A)説明可能AI(XAI)
一般に機械学習、特に深層学習によって学習されたモデル(AIの本体)は数学的に複雑な式で表現されており、「プロセスの説明」が困難である。一方で、利用者の視点では、このようにブラックボックス化されたシステムは許容できないケースも少なくない。
近年では、上記のようなケースにおいてAIが何らかの予測・判定を行った際に、「ある程度の」理由を提供できるようなAIが研究・開発されている。これを「説明可能AI (XAI)」と呼ぶ。XAIでは、例えば物体認識では「画像中のどの部分に着目して結果を判断したか」を出力可能とする試みがあるなど、「入力されたデータ(特徴)のどれを重視したか」を算出しようとする。
ただし、機械学習に関してはある意味で「説明可能性、解釈性を犠牲にして精度を上げている」側面もあるため、XAIに限らず、目的に応じた手法の選択が必要である。
B)敵対的生成ネットワーク(GAN)
敵対的生成ネットワーク(GAN)[*1]とは、データの生成プロセスに着目し、その生成プロセスを学習することで、「リアルな人工データを生成」することを目的としたモデルである。
この技術は、例えば画像の欠損部分の補完や低解像度→高解像度の変換、白黒画像の着色、言語間の翻訳、文章の自動生成などに利用される。また、データの「水増し」のために実データに近い擬似データを生成するために用いられる場合もある。
C)転移学習
転移学習とは、あるデータで抽出された特徴あるいは学習されたモデルを別の(似た)データに適用し、後者における学習の効率化を図る方法である。転移学習は、形式的な定義はなく、また、転移対象によっていくつかのアプローチに分けられるが、ここでは簡単に説明するために、「データが十分に得られるドメインで学習されたモデルをベースに、データがあまり得られないドメインの学習を行う」こととする。
例えば、画像認識のためのモデルは一般に非常に大規模な学習用のデータを必要とするが、画像認識システムを実現したいユーザがそのようなデータおよび学習のための環境を持っているケースはまれである。このような場合、既に大規模データで事前学習されたモデルを「初期モデル」として利用し、目的に応じた追加データのみで再学習を行うことで、高い精度のモデルを比較的少数のデータで学習することができる。図表2は転移学習のイメージである。
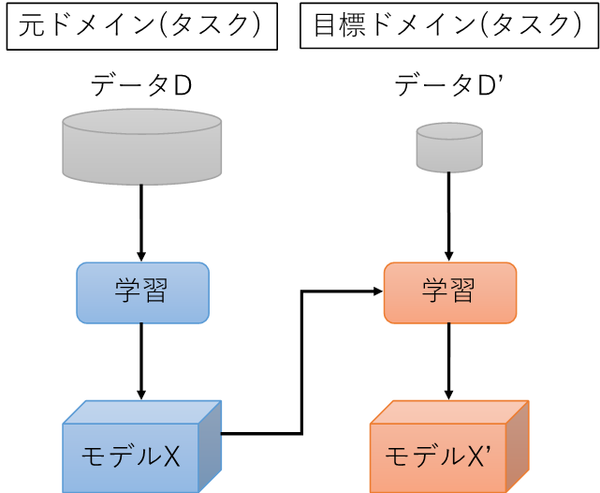
【図表2:転移学習のイメージ】
D)BERT
前述の転移学習は主に画像関連タスクでその有用性が確認されてきた。一方で、BERT [*2]は自然言語処理における事前学習のブレイクスルーとなる技術である。
通常、自然言語処理に用いられる学習では順方向(英語の場合左から右)へ単語列を読み込んで予測を行う。一方BERTはそのようなモデルとは異なり、双方向(左右両方)から文脈を予測することで、高精度なモデルを実現する。またBERTは「事前学習モデル」であり、上述の仕組みにより自然言語の汎用的な表現(言語モデル)を事前学習することが可能となる。得られたモデルを個別タスク向けに再学習(転移)することでタスクごとにゼロから学習することなく、効率的に高い精度のモデルが得られる。
次に、AI導入を考える際に候補となるいくつかの実装方法について説明する。
AIを利用する際には、利用者のスキルや利用目的に応じて、主に以下の三つが選択肢として挙げられる(図表3)。
①プログラミング言語 / オンプレミス
②クラウドサービス
③エッジAI
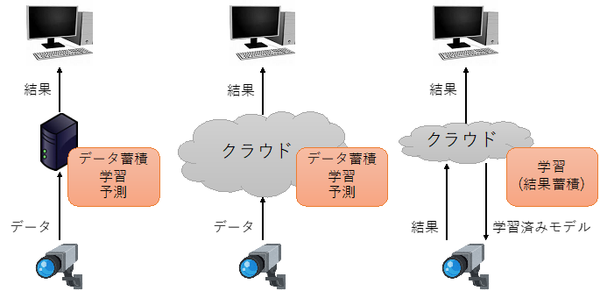
【図表3:AIの実装方法】
以降で、それぞれの特徴について言及する。
① プログラミング言語 / オンプレミス
機械学習を手軽に実装、検証可能なプログラミング言語として代表的なものに「R言語」や「Python」が挙げられる。これらの言語では、多くの機械学習ライブラリが利用可能である。近年の機械学習関連の論文では、論文中の手法をPythonで実装したものをGitHubなどで公開することも多く、最新の手法を検証することも容易となっており、検証フェーズ(Proof of Concept : PoC)ではこれらを利用することも多い。
オンプレミス環境でAI活用を行う場合には、AIのコアとなる部分をこれらの言語で実現し、周辺機能を他の言語で実装する方針を採用することで、開発コストを低く抑えることができる。
② クラウドサービス
近年はクラウドサービス上で機械学習を利用するための機能を提供しているものもある。代表的なものとしては、「Amazon Machine Learning」「Microsoft Azure Machine Learning」「Google Cloud Machine Learning」が挙げられる。
これらのサービスを活用する利点は以下の通りである。
●GUI操作などにより比較的利用しやすい
●WebサーバやDBサーバなど他の機能と連携しやすい
●検証と運用を同一環境で実現可能である
●ローカル環境を整備する必要がない
●大規模データに対してもスケーラブルに処理することができる
上記のようにクラウドサービスは多くの利点があるものの、データに対するポリシーなどの理由により、クラウド環境にデータを置くことが許されていない場合もあり、これらのサービスの活用は、検討はしているものの実現していないケースも少なくない。
➂エッジAI
時々刻々得られる大量のデータを全て(どこかに置かれた)サーバに送信・蓄積すると通信量やストレージ、処理負荷の観点でコストが高くなる。近年は、現場にある「デバイス」側で何らかのデータ処理・予測・判断を行う「エッジAI」が注目されている。これにより、個々のデバイス内で完結した処理が可能となり、サーバ側へ通信や処理も低く抑えることができる。
エッジAIの代表的な利用シーンとしては、
●自動車の自動運転における画像認識
●生産設備の状態監視
●監視カメラなどによる画像認識
●スマートフォンなどに搭載された音声認識(モバイルAI)
などが挙げられる。
これまで見てきたように、AI活用に関しては、課題や対象とするデータ、利用可能なツール・サービスなどいくつかの観点で検討を進めていく必要がある。この点については、次項で詳しく述べる。
3 AIの業務実装時のプロセス
業務課題解決のためにAIを活用する際によく採用されるプロセスについて、筆者の経験を交えながら述べる(AIを用いた「新規サービスの創出」はこの限りではない)。
一般にAI活用の検討は以下のような進め方が取れられることが多い。
①課題整理
②データ取得 / 整理
③PoC
④プロトタイプ / 運用システム開発
① 課題整理
あらゆる課題をAIで解決できるわけではなく、その事実は多くの人が認識している(はずである)。一方で、「どのような課題がAIによる解決に向いているか」は自明ではない。さらにAI適用可能な課題であっても、求められる成果(精度や効率化)が得られるかどうかは、実際に検証を実施するまではわからないことが多い。
このフェーズでは、業務課題を整理し、AI(あるいはデータ活用)による解決の可能性がある課題を抽出する。AIにはエキスパートシステムのようなルールベースの技術やシミュレーション技術、オペレーションズ・リサーチに属する最適化技術なども含まれるため、課題の特性や目的、期待される出力(成果)に応じてどのような技術を用いるか適切に判断する必要がある。
また、この段階で、AIを実装する対象業務のフローをどう変えるか(改善するか)を計画し、現場のコンセンサスを得ておくことが重要である。筆者の経験上、AI導入を主導している担当者と利用者が異なる場合(例えば、前者がIT部門、後者が工場の現場技術者など)、利用者不在で検討を進めてしまうと、業務実装時に計画が頓挫、もしくは実装後に使い物にならないシステムが仕上がる可能性がある。
② データ取得 / 整理
解決すべき課題を抽出し、そのために必要なデータを収集する進め方が、古典的な(あるいは、手堅い)方法である。しかしながら、IoT技術の発達に伴い、「ひとまず役に立ちそうなデータを集めておく」というケースも多い。この場合は①課題整理と②データ取得/整理が逆転することになる。どちらの場合においても、実際にデータ分析(PoC)に移る前に、収集したデータをある程度整備し、課題解決に有用と思われるデータを取捨選択しておくことは重要である。
③ PoC(概念実証)
このフェーズでは、「実際の利用者の視点で」期待される精度・効果が得られるかを実際のデータを用いて評価するとともに、システムの開発・導入までに解決すべき課題の抽出およびその解決を試みる。
①にも記載したが、この段階でも「PoCの結果としてどのような効果・結果が得られそうか」といった導入者側の見解と「何があれば嬉しいか」という利用者側の見解をすり合わせることで、後続の開発がスムーズに進む。
なお、期待される精度・効果が得られることがほぼ確実な場合やスモールスタートでいったん「動くもの」を整えた上で精度向上等を進めていくような場合には、このフェーズは必ずしも必要ではない。
④ プロトタイプ・運用システム開発
予算や開発スケジュールなどにもよるが、運用システムの開発・導入前にプロトタイプとなる小規模なソフトウェアを開発し、実地での利用・評価を行うことで、より効果的なシステム開発が可能となる。プロトタイプが不要な場合は、システムの運用時に随時利用者からユーザビリティや精度に関して要望を抽出し、改修を行う運用・保守方法が望まれる。
AIを含むシステムは従来のウォーターフォール型の開発とは異なり、データの変動による精度変化や新規AI技術への追従など、比較的短いサイクルでシステムやモデルの改修を繰り返す必要がある。したがって、導入後に関しても、上記を考慮した改修予算・スケジュール・体制を整えておくことが肝要である。
なお、「AI(機械学習:ML)」は業務システム全体のごく一部であり、
●データの収集・蓄積・管理・加工の仕組
●学習過程と得られるモデルの管理
●結果の正しい解釈と活用方法
●想定する利用者
など、「AI以外のシステム(機能)」も重要である(図表4)。
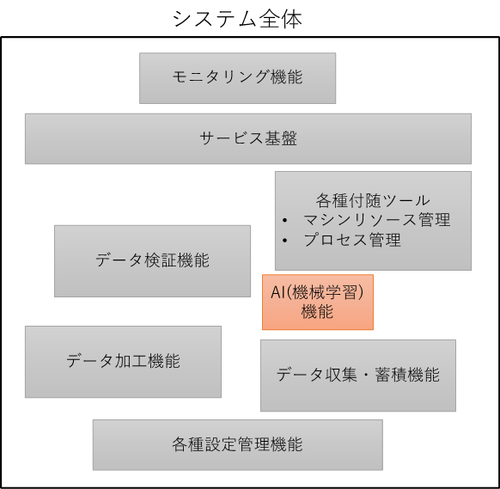
【図表4:システム内のAIの位置付け】
文献[*3]ではAIシステムを構築・利用する上での留意点が以下のような観点で言及されている。
●システムと実世界の間に常にデータが介在するため、システム内やシステム間の境界が引きづらい
●データ依存性が高く、従来型のシステムよりも不具合箇所などの特定がしづらい
●リリース以前にシステムの挙動を予測することが難しい
●設定すべき対象が非常に多い(使用するデータ項目、アルゴリズム固有の設定、前 / 後処理方法、検証手法など)
いずれにせよ、AIシステムの利用にあたっては、従来型のシステムとは異なる観点での開発・保守を必要とする。
最後に、筆者の経験から二つの観点でAIシステムの導入方針について述べる。
一つ目は、前述のようにPoCから検討を進めていく方針である。これまでに、既製のAIツールを導入したがうまくいかず、アルゴリズム検討(PoC)からお願いしたいという相談をされたことも少なくない。専門性あるいは個別性の高い課題に関して、このようなケースが多く、AI技術者の経験に基づく試行錯誤的なデータの選定や前処理・アルゴリズム検討などが求められる。
二つ目は、既製のAIツールを利用する方針である。「一つ目」で述べたようなケースはあるものの、既製のツールを用いて検討がうまく進められている話も実際にある。データ活用の初期検討や課題の洗い出し(業務フローのどの部分を重点的に考えるべきか)に利用しているケースが多いように見受けられる。ただし、AI・人工知能EXPOなどでも多く出展されているように、AIツールは数多く存在し、各ツールが対象とする業務課題やデータ、精度はものによって異なるため、既製ツール導入にあたっても、有識者に第三者的な観点での助言を得ることが肝要である。
4 まとめ
本稿ではAIに関して概観した。AI技術は、手法(理論、アルゴリズム)の点においても、それを業務活用するための基盤の点においても、日々新しい技術が提案・提供され続けている。また、課題によっては必ずしも最新のAI技術が最適な解決方法でないこともある。AI導入に際しては、上記の状況にあることを踏まえつつ、課題に合わせた適切なステップで検討を進めていくことが重要である。
参考文献
[*1]I. Goodfellow et al. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27, 2672-2680, 2014.
[*2]J. Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv: 1810.04805, 2018.
[*3]D. Sculley et al. Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems 28, 2503-2511, 2015.
#AI#論文
- この記事をシェアする
- この記事はいかがでしたか?